Renjin presented at the R Summit & Workshop in Copenhagen
As a follow-up to last year's Directions in Statistical Computing meeting in Brixen, this year sees the R Summit & Workshop coming to Copenhagen. And like last year the groups behind the alternative R interpreters are presenting the current status of their efforts. This includes Renjin, the interpreter that runs in the Java Virtual Machine. So this was a great opportunity to present the first results of Hannes Mühleisen's research project in collaboration with BeDataDriven.
Below are the slides from the presentation and we will highlight some of these in the remainder of this article.
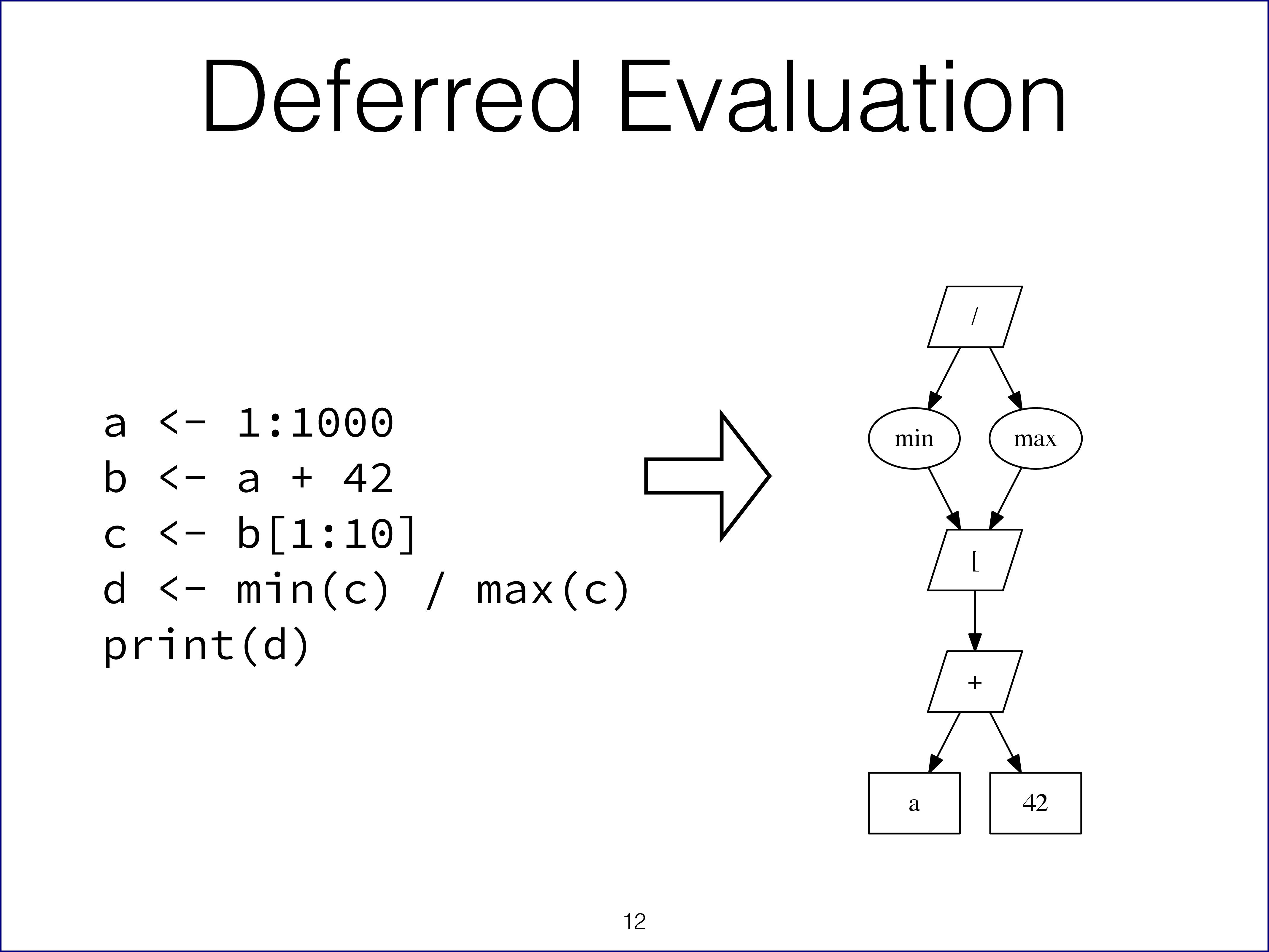
The key idea of the R as a Query Language is to use Renjin's ability to defer computations (or evaluations): the interpreter will not do any work until a result is needed, for example when the result of a computation must be printed to the console with the print() function. Once the interpreter gets to such a point it has a picture, a graph, of the computation up to that point. With this graph, the interpreter can decide how to execute these computations in an optimal way much like a database optimizes the execution of a query written in SQL (hence the name of the project). Slide 12 (shown below) has an example of how a snippet of R code is translated into a call graph.
Once the interpreter needs to produce a result it will look at the execution graph and apply one or more optimizations. Slide 10 (shown below) lists a few of the optimizations that we have implemented so far.

Let's discuss a few of these in more detail and start with selection pushdown as shown in slide 13. It contains the following (contrived) example which includes an expensive calculation (i.e. the factorial) on a (potentially very large) vector a, followed by a selection of a small subset of the result. This may seem like something you obviously never do, but is not uncommon in longer and more complex programs.
b <- factorial(a) # 'a' is a large vector
# ...
b[1:10]
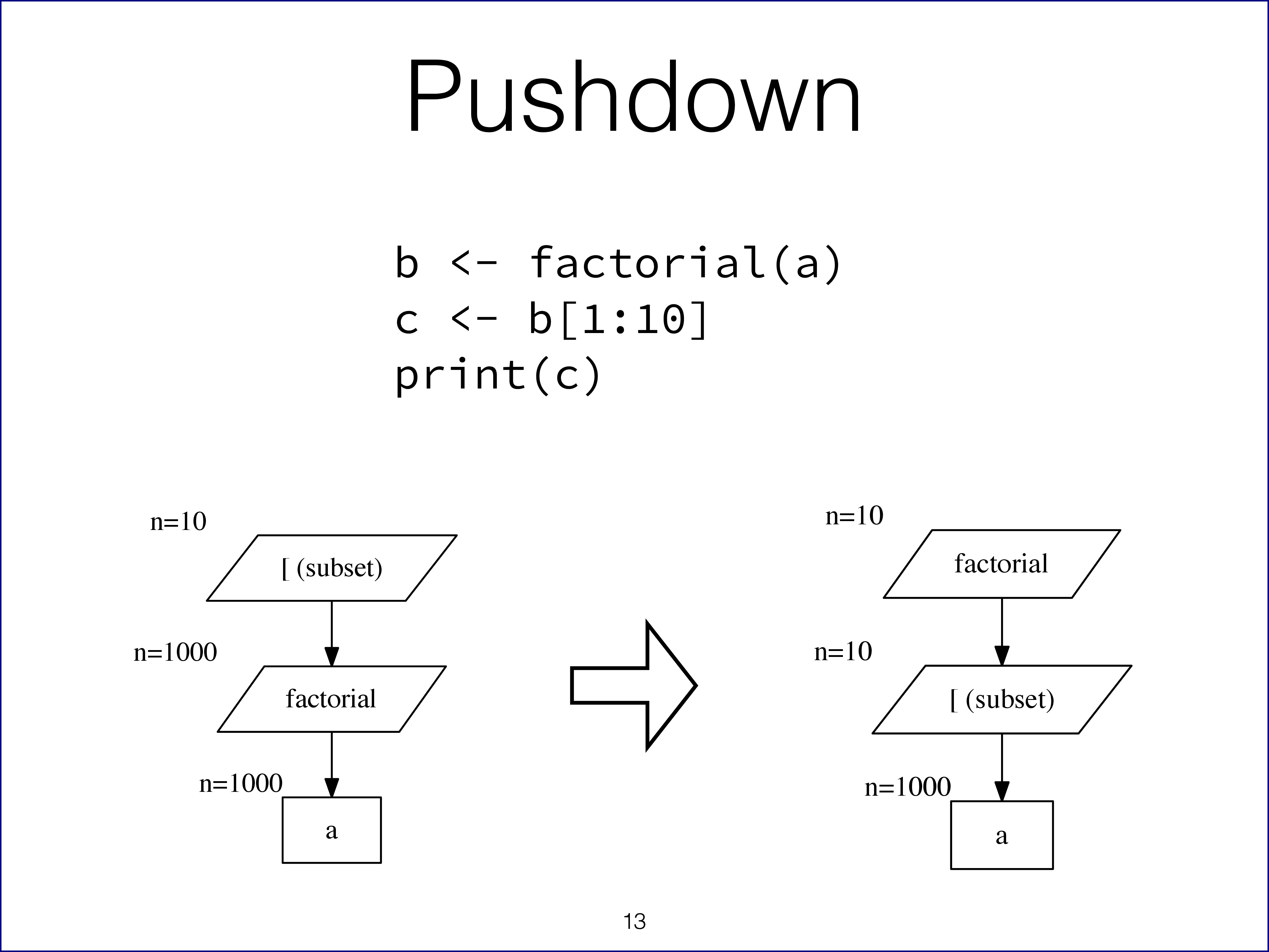
In essence this optimizer ensures that we don't do unnecessary calculations if we only require a (small) subset of these in the end. The pushdown of the selection operator [ by the interpreter means that it has automatically converted the code above to the equivalent of factorial(a[1:10]).
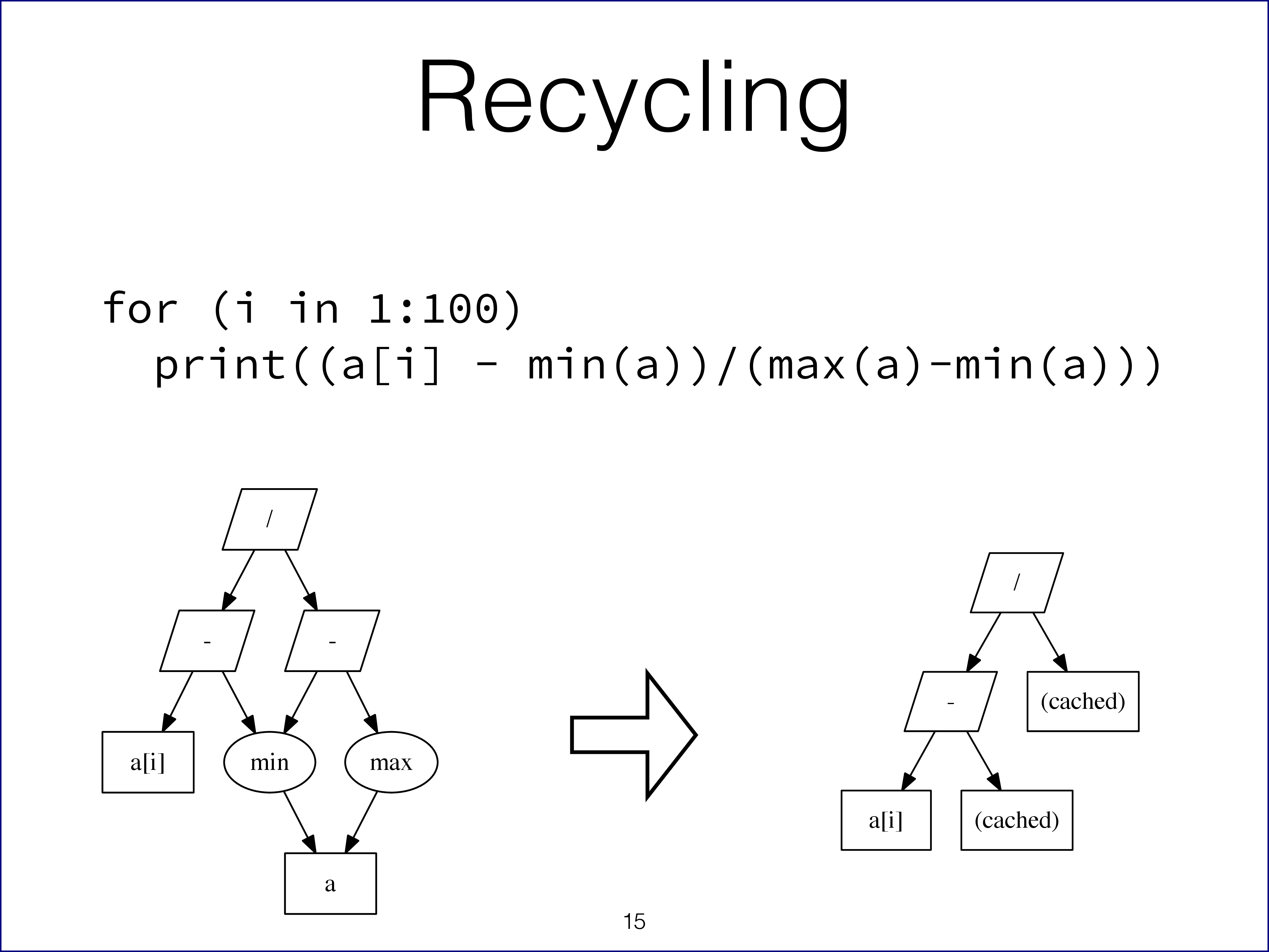
Then we show an example of common expression elimination which means that we recycle parts of the calculation that we have already performed earlier in a loop. In the following example code, the vector a doesn't change while in the loop so it is not necessary to calculate min(a) and max(a) in every iteration of the for loop.
for (i in 1:100) {
print((a[i] - min(a))/(max(a) - min(a)))
}
As is shown in the slide, these parts of the iteration get cached and reused.
Unlike GNU R, Renjin treats vectors as immutable objects which enables not only the recycling of sub-expressions but also implicit (i.e. automatic) parallelization. This means that the interpreter will assign different code paths to multiple threads if these are available. No special packages or human intervention required!
Finally, the last slide (shown below) compares the computation times of GNU R versus Renjin (with and without optimizations) for an experiment with the survey package. Unlike the micro-benchmarks discussed earlier, this is a realistic use-case that is also very typical of the type of calculations that R is used for. The data comes from the American Community Survey and the experiment involves the calculation of the average age using replication weights.
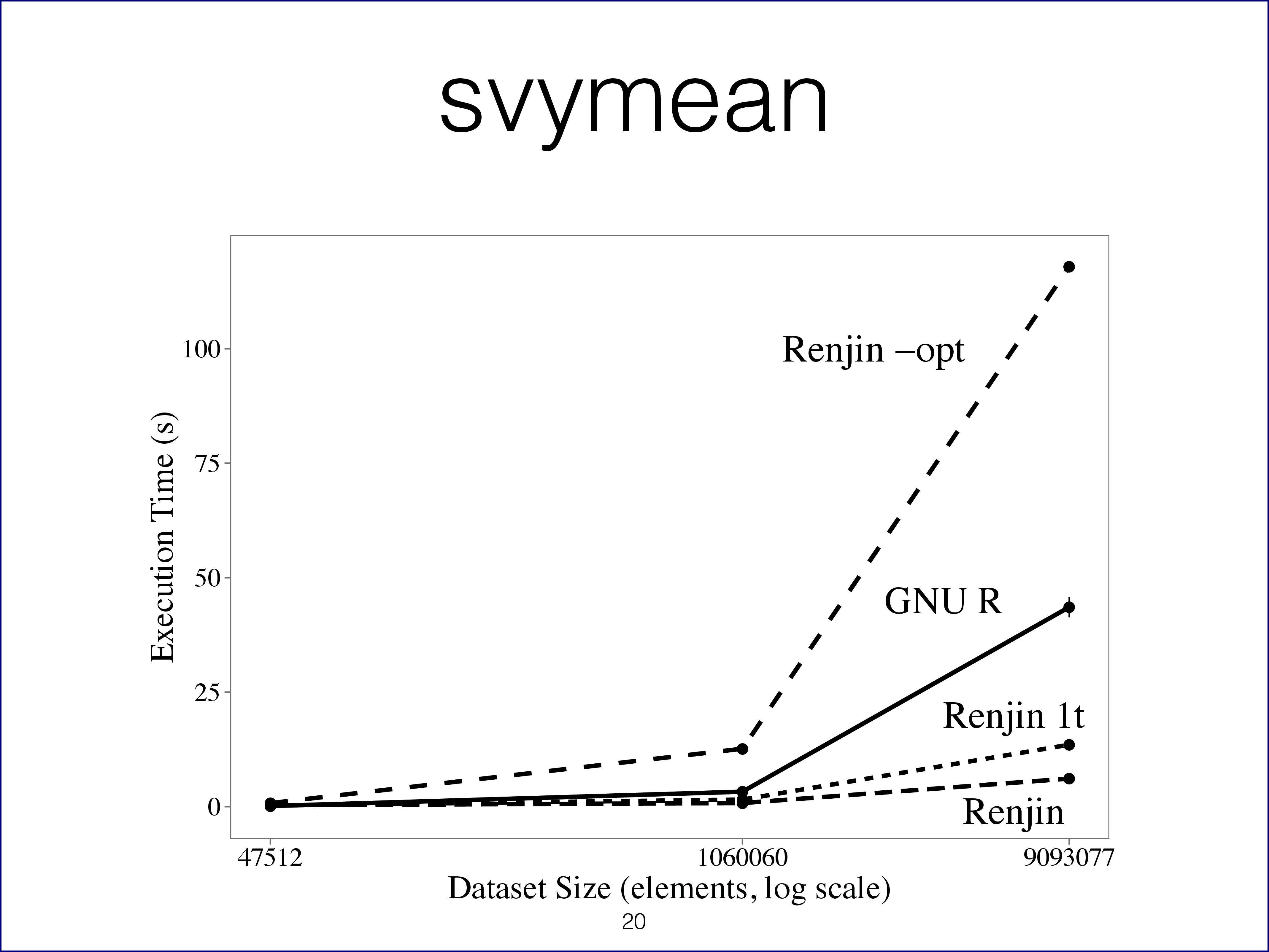
Renjin is slower than GNU R (version 3.1.3 in this case) if no optimizations are applied (Renjin -opt). We attribute this to the use of virtual function calls in the JVM versus the tight C loops on arrays used in GNU R. In other words: Renjin's flexible architecture comes at a cost. But the whole point of this flexible architecture is to improve performance in a strategic way, i.e. not by local optimizations or band-aids. Once we enable all the optimizers in Renjin, it dramatically outperforms GNU R even if given only a single thread (Renjin 1t). Using multiple threads (Renjin) the computation time goes down even more, but this experiment didn't lend itself very well to parallelization. So the benefits of these optimizations demonstrated with the micro-benchmarks translate to greater performance in realistic use cases.
So what's next? We have only touched the surface of the type of optimizations that can be considered for the execution graph of an R program. We would like to expand these to include cost-based optimization techniques, where alternative execution graphs are enumerated and ranked using a cost model. Such cost-based optimizers can be used to decide if parts of the work can and should be shipped to a specialized worker such as a database or a GPU.
Read more at Renjin's blog or subscribe to the blog's RSS feed.