Renjin on Spark
Researchers from Purdue University and Huawei Technologies have developed a new framework called RABID which combines Spark with Renjin.
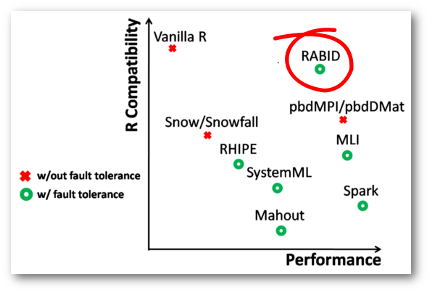
The authors choose to use Renjin as the default R interpreter because “it [Renjin], like Spark, is implemented in Java, and consequently can be better integrated with Spark”. According to the study, by using Renjin, worker processes can share the cached dataset copy of Spark worker and, hence, “reduce both latency and memory overheads”. In subsequent study, the authors used RABID with their VM scheduling algorithm for efficient scheduling of Virtual Machines in a data center, reducing the number of physical machines by 15% and helped to make our planet more green.
You can access the publications here and here.
David Russell (onetapbeyond) has also written an Apache Spark package called Apache Spark Renjin Executer (REX) “to let Scala and Java developers use R from Spark.”

Read more about REX.
In our October newsletter we informed you about improvements we made to Renjin as part of our collaboration with a US-based medical technology company to integrate Renjin in their Spark cluster. Read the newsletter here.
Finally, related to this subject is a recent post about using Renjin on Google's Cloud Dataflow service. Like Spark, it is a Java-based service which allows you to build data analysis pipelines to be executed in parallel on Google's massive computing infrastructure. Renjin allows you to integrate an R interpreter in these pipelines, which is impossible to do with GNU R.
Tell us about your experience with R(enjin) and Spark!
Read more at Renjin's blog or subscribe to the blog's RSS feed.